Cloud Guru Challenge - September 2020
I gave the #CloudGuruChallenge by Forrest Brazeal (A Cloud Guru) for September a go! I started 1 day before the deadline, so rushed to finish a bit. The next challenge will be worked on straight away, and the Readme files will definitely have more than just titles. “Working software over comprehensive documentation” right?
Here’s some of the stuff that I did! Read the challenge details here: https://acloudguru.com/blog/engineering/cloudguruchallenge-python-aws-etl
Here’s the basic architecture of the solution:
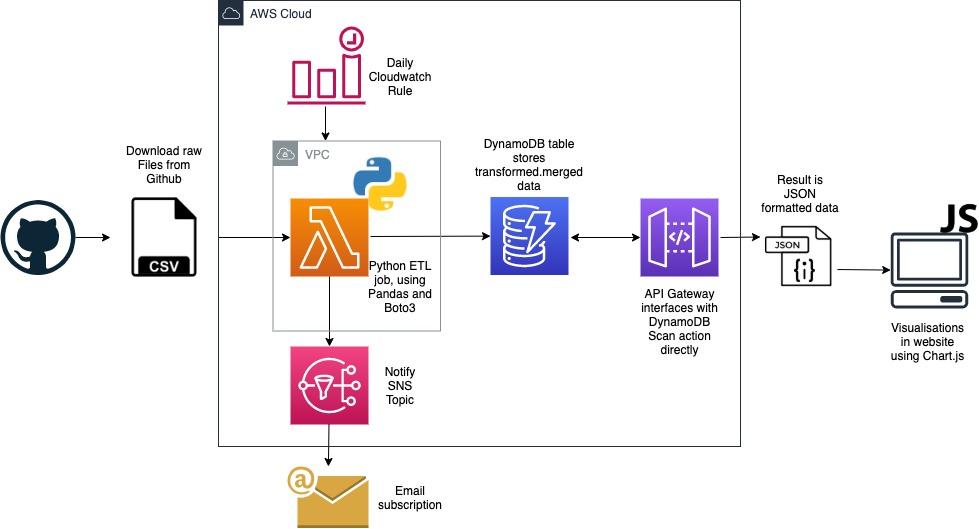
See my code here: https://github.com/simonmackinnon/cloudguruchallenge/tree/main/2020-09
ETL Job using Python
The job runs automatically using a CloudWatch scheduled rule, once per day. Setting this up was pretty straightforward. One gotcha for people is that a CloudWatch rule needs permission to invoke Lambda functions.
It then loads data and puts it into DynamoDB table. I had a pretty fun time coding this. I hadn’t used the Pandas Python library before, so it was good to see the power of it. Some time (what feels like almost a lifetime) ago, I learnt to use R to do data science. This was a pretty similar experience (although zero-indexing helps!). Some of the nuances of the challenge were around only loading the most recent day’s data, so some smarts had to be built into it for that to work. The merge functionality helped to spead up the work
It send SNS notifications for different status updates. I set this up as per the brief, although I was pushing to my topic for every row that couldn’t be read correctly, which proved to be a little verbose (at one point I was sending hundreds of error notifications due to a bug in my code). Pretty fun and easy to set up. Then getting CloudFormation passing the output ARN to the environment variables of the Lambda function kept this relatively re-deployable.
For Reporting, I used API Gateway to expose the DynamoDB table data, and then consumed it in JavaScript. Some of the gotchas in this (a) while the API request type for performing Scan operations is GET, the HTTP method for DynamoDB service calls is always POST (b) I found getting the Integration Request Mapping Template and the Integration Repsonse Mapping Template are right for this is a little difficult (c) ensuring the calls to the API had the correct headers to avoid a CORS / Preflight error is always difficult (and something I should spend some time learning about, it always trips me up). I built a simple vanilla JS demo site (due to time constraints) to retrieve (and sort) the data, then display using Chart.js
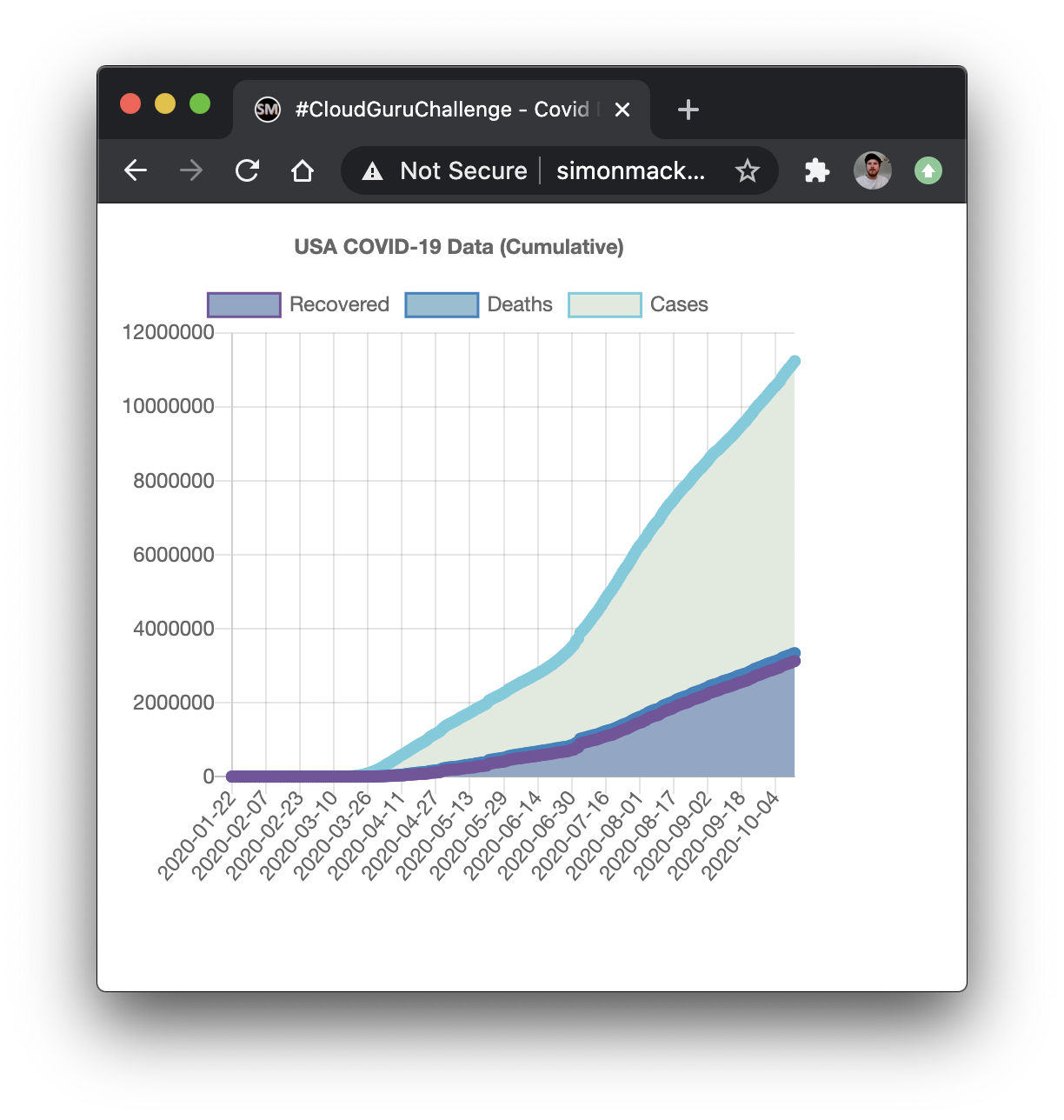
Anyway, you access the data URL here:
https://2tp0wsvdr2.execute-api.ap-southeast-2.amazonaws.com/live/cumulativedata
And you can see the graph output here:
http://simonmackinnon.com/cloudguruchallenge-2020-09.html
Infrastructure as Code
Everything is defined in CloudFormation (except uploading function package to S3 and publishing new versions) Some of this was HAAARD… especially setting up API Gateway to expose the DynamoDB data without using Lambda. This is relatively easy in the console, but I found some of the settings difficult in YAML/CloudFormation. As mentioned above setting the Mapping Templates for the request/response continuoulsy lead to formatting issues… until it didn’t.
TBD:
- Lambda layers: the package built was little big, and some of that could be reduced by using layers, especially for the Pandas library
- VPC infrastructure was a little overboard for single lambda
- CodePipeline to test and publish ETL job function package
- CodePipeline to update infrastructure on update
- Build React site to display more interactive/multiple graphs
- API Keys / Security